Teaching avatars to remember your face

Creating lifelike animated avatars that look and behave like real people is no longer science fiction—it’s a frontier in graphics, virtual communication, and entertainment. However, one challenge persists: how do we ensure that avatars not only move realistically but also faithfully preserve identity-specific details like wrinkles, tattoos, and subtle facial textures?
That’s the question our recent paper [1] tackles. We introduce a novel, lightweight personalization technique for head avatar generation—one that preserves fine facial details with fidelity, while maintaining the model’s efficiency.
Making Avatars More Like You
Modern avatar animation systems are built with generic models trained on large datasets of many faces. These models, such as GAGAvatar [3], are great at learning general facial behavior and animating new identities with no additional training. However, because the model is trained over hundreds or thousands of people, it tends to “smooth over” unique features—like facial scars, tattoos, or a textured skin region.
Researchers have tried to address this issue through model adaptation: fine-tuning the avatar to new identities using limited data. Among these techniques, LoRA (Low-Rank Adaptation) [4] has become popular for its parameter efficiency. It works by injecting small, low-rank, trainable matrices into the original model's layers, making it possible to adapt models without retraining them from scratch.
But LoRA alone isn’t enough.
Why LoRA Alone Misses the Details
While LoRA can help avatars mimic general identity features on the face, it struggles with the high-frequency details—the subtle, textured regions of the face that truly distinguish one person from another. These are often under-highlighted in the latent space that generic features encoded from DINOv2.
Our research finds that LoRA, when applied naively, cannot guide the model to focus on the right parts of the feature space. That’s where we introduce a key innovation: a Register Module that enriches LoRA's adaptation process by learning where to look and what to emphasize.
A 3D Register That Learns to Pay Attention
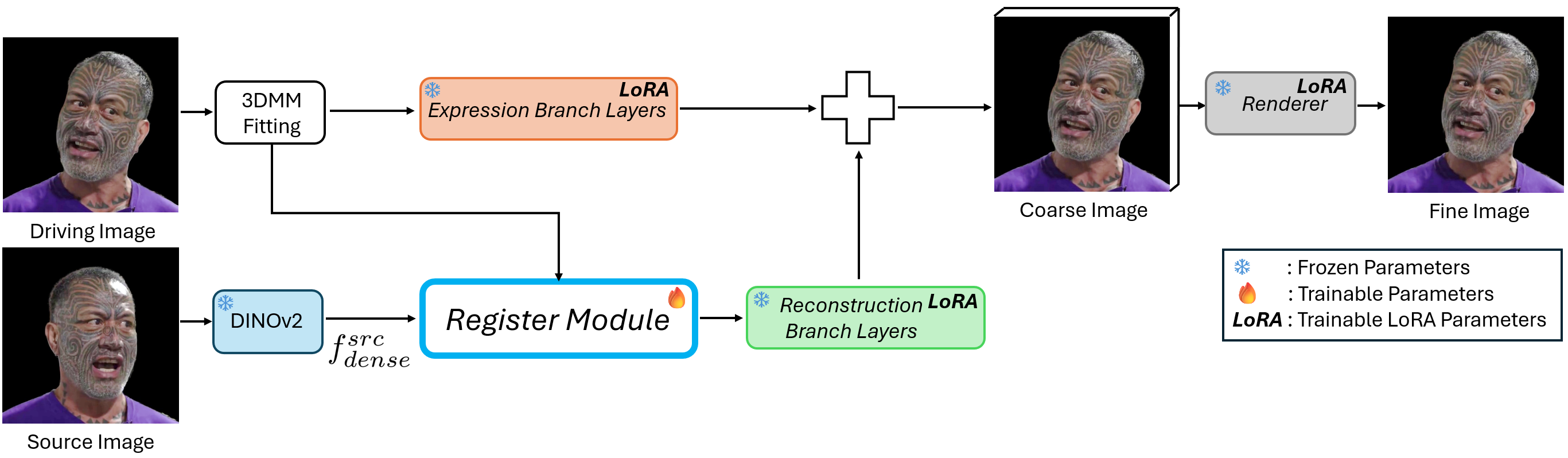 Figure 1: This diagram shows the overall model training framework, including the Register Module that is designed to enhance LoRA training and capture identity-specific details on the face during model adaptation.
Figure 1: This diagram shows the overall model training framework, including the Register Module that is designed to enhance LoRA training and capture identity-specific details on the face during model adaptation.
Our Register Module is inspired by the idea of "register tokens" from Vision Transformers, which are additional tokens that help networks store and reuse important global information. Here, we design a Register Module to inject identity-specific 3D features into the intermediate DINOv2 feature space (see Figure 1). This enhanced feature map guides LoRA to focus on key facial regions, enabling better personalization.
Specifically, we generalize the concept of “register tokens” into a 3D feature space tailored for human faces. The module rigs learnable embeddings to a 3D facial mesh and projects these features into the image space using camera parameters. Through interpolation and CNN-based encoding, the Register Module produces a refined feature map that is added to the DINOv2 features, enhancing LoRA training to capture identity-specific details.
Importantly, this module is used only during adaptation—it’s discarded at inference, ensuring that the runtime speed is unaffected.
How the Register Module Helps
The Register Module acts like a teacher for LoRA during training. It highlights the critical areas in the feature space—typically where facial details lie—and dampens background or irrelevant information. This guidance enables LoRA to better capture identity-specific cues.
Quantitative evaluations back this up. The table below presents LPIPS (lower is better) which indicates visual quality based on perceptual similarity, and ACD (lower is better) reflects identity preservation based on facial recognition embeddings. On two datasets—VFHQ and our newly introduced RareFace-50, which includes individuals with distinctive facial traits—the method significantly outperforms baseline methods.

In simpler terms, lower LPIPS means better visual similarity, while lower ACD means better identity preservation. The proposed method wins across the board.
Seeing Is Believing

Words and metrics only tell part of the story. Visually, the improvements are striking: (1) Wrinkles and veins that are washed out in other methods now persist across expressions. (2) Tattoos and skin textures are preserved. (3) Blemishes, laugh lines, and skin roughness stay intact through complex facial motions.
This is especially apparent on the RareFace-50 dataset. Our paper [1] and website [2] include more visualizations showing how our Register Module “teaches” the model to pay attention to faces and ignore background clutter. What we have achieved: personalized avatars that don’t just move, but also look like you in detail.
[1] Low-Rank Head Avatar Personalization with Registers (https://arxiv.org/abs/2506.01935)
[3] Chu et al., Generalizable and Animatable Gaussian Head Avatar, NeurIPS’24
[4] Hu et al., LoRA: Low-rank Adaptation of Large Language Models, ICLR’22