Teaching AI when to speak and how to react
Imagine you’re chatting with a friend. As they talk, you might nod, say “yeah”, or add a quick “okay”. These small, seemingly simple reactions, known as backchannel responses, help conversations feel natural and connected. They show you're listening and engaged, all without interrupting the speaker. While this kind of communication comes naturally to humans, it's a whole different story for machines. Today’s advanced AI systems, like ChatGPT, are great at responding once you’re done talking. However, they’re still missing something crucial in natural conversation: the ability to react in real time, like a person would. They don’t yet know when to chime in with a quick acknowledgment or a well-timed “got it” while someone else is still speaking. And that’s a problem if we want AI to participate in conversations as smoothly as people do.
Why Timing Matters in Conversation
Good conversation isn’t just about what you say. It also depends on when you say it. A delayed “yeah” or an early “I agree” can feel awkward or disrupt the flow. Humans use tone of voice, facial expressions, pauses, and body language to judge the right moment to speak or respond. Most existing conversational AI models, however, don’t have access to all these signals. They usually rely on a text-based pipeline. Spoken words are turned into text using speech recognition, processed by a language model, and then converted back into audio with text-to-speech. This process often misses important visual and audio cues that people naturally use in real conversations. There's another issue too. These AI models are mostly trained on written text, such as books and websites. Written language is more formal and structured, while real conversation is messy, fast, and filled with shared context. Because of this, AI systems struggle to understand the timing and subtlety of natural dialogue.
A Smarter Way to Train AI to Listen and React
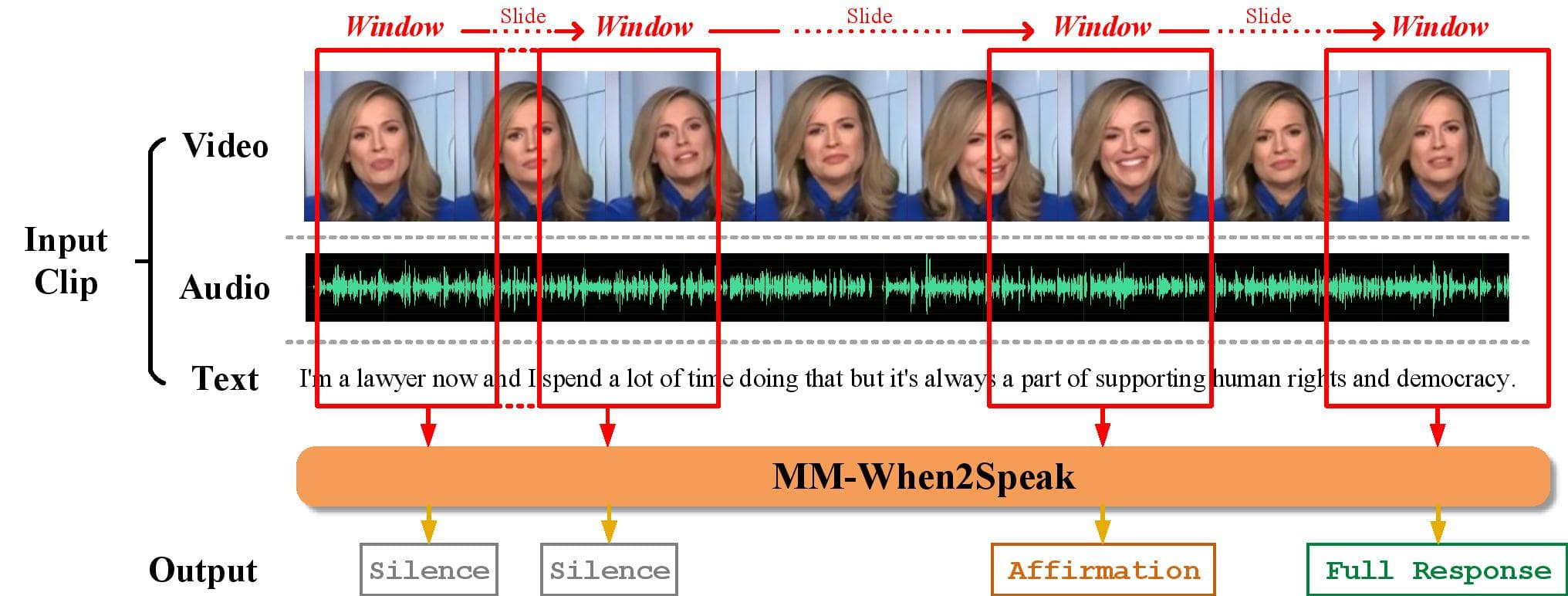
To solve this, in our recent paper [1], we created a new approach to help AI learn not just what to speak, but also “when to speak“. We built conversational datasets using real conversation videos from public online platforms. This dataset includes video, audio, and text so the AI can learn from the full range of signals that humans use. We processed each video into short clips and labeled each one as either silence (non-speaking), full response (start speaking), or one of several short reaction types, such as affirmations, greetings, expressions of surprise, and questions. This helps the AI understand different kinds of listener responses and the cues that lead up to them.
Using this dataset, we developed MM-When2Speak, a new AI model that combines visual, audio, and textual information to decide if it should respond during a conversation, and what kind of response to give. The top figure provides an overview of the system. At its core, each modality is first encoded separately, then concatenated and passed through self-attention layers, enabling the model to focus on the most relevant cues across time and modalities. A final classifier determines whether to stay silent, give a brief reaction, or offer a full response. Unlike traditional models that wait for a speaker to finish, MM-When2Speak can decide both when and how to respond, making conversations with AI feel more natural.
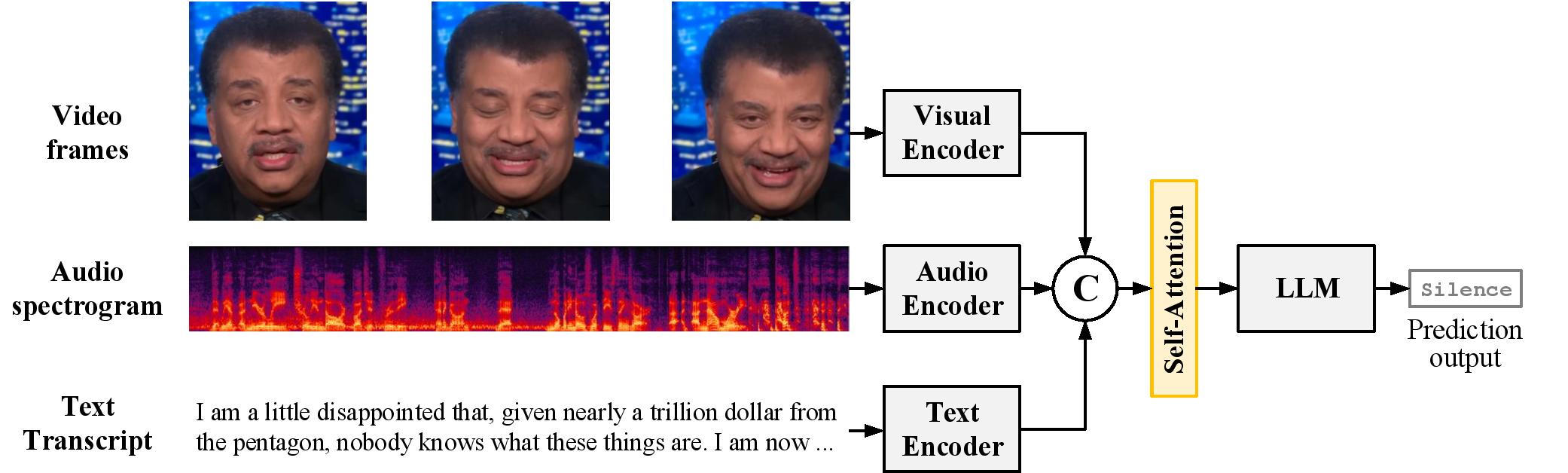 Figure 1: The diagram shows the architecture of MM-When2Speak, which encodes visual, audio, and textual inputs separately, then combines them using self-attention to capture critical cross-modal and temporal cues.
Figure 1: The diagram shows the architecture of MM-When2Speak, which encodes visual, audio, and textual inputs separately, then combines them using self-attention to capture critical cross-modal and temporal cues.
Knowing When to Speak—and When to React—Makes AI More Natural
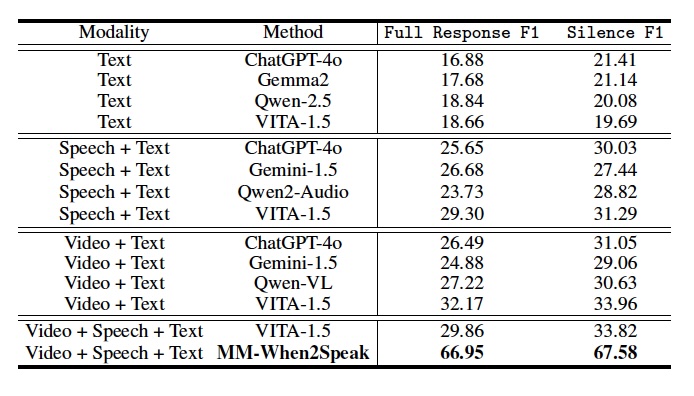
We tested MM-When2Speak against top large language models (LLMs) using different modality combinations. The table below presents F1 scores for both silence (non-speaking), full response (start speaking) classifications. Our model consistently outperformed others, demonstrating the value of integrating visual, audio, and textual signals. This shows that going beyond text alone is essential for building AI that can engage in more natural, human-like conversations. For the results of the short reaction types, we find similar trends and we refer the readers to check more results in our paper [1].
If we want AI to truly understand us and take part in our conversations the way people do, timing is everything. With MM-When2Speak, we are one step closer to making AI that not only knows what to say, but also knows the perfect moment to say it.
Want to hear what natural real-time reactions could sound like?
This is an example of one user speaking with our interactive avatar (Steve) that provides timely backchannel feedback, powered by our MM-When2Speak. To make the interaction human-like, for example, around 0:36, Steve interrupts the user to raise a point. In addition, Steve is able to constantly make short reactions like “yeah” during proper timings.
[1] Beyond Words: Multimodal LLM Knows When to Speak (https://arxiv.org/abs//2505.14654)